Assumptions and observations:
So basically, AI consumes and learns from human productions to generate its own neural networks and concepts, being then able to produce information by reusing and combining these concepts. Therefore a simple-to-ask but hard-to-answer question comes to our human minds: if we let AI models generate the next generation of data, will they be able to learn new things by reprocessing their own production or will they reach a glass ceiling and stop their until now so fast evolution?
According to the Stanford University HAI 2025 report1, the size of publicly available data for AI training is drastically shrinking, as more and more websites implement protocols to prevent data scraping. The estimation of the amount of protected data on the internet jumped from 5-7% in 2023 to 20-33% in 2024. Moreover, in the same report, the date for the current stock of data to be completely processed is estimated somewhere between 2026 and 2032. Note that there could be a scenario where data training with public data would stop due to the fact that the bigger the model is, the less it improves with more data.
Therefore, comes 2032, AI models will stop consuming the public data on the internet. What then? Have AI reached their peak capabilities? Will the trend suddenly die, leading to a huge crash in the AI market?
 Why mention abstract art in the title of this blog?
Why mention abstract art in the title of this blog?
In the early twentieth century, a huge change quaked the art community. Meet below the Violin from Georges Braque2. Whether you’re an expert or a neophyte when it comes to art, there are two observations we can make while watching this picture:
1. This picture shows a violin.
2. This picture doesn’t represent a violin.
The big change at this time is the realization that human beings can represent something without having to exactly show it. We can make another human being understand the concept of a violin without having to precisely figure a violin. This consideration opened the door to a new form of art, where you can transmit concepts and feelings to your pairs without having to copy a scene from the material world. We can produce art without having to represent Nature itself. Human beings transcended their material condition by realizing their power to produce outside of Nature.
Then all the abstract era in art confirmed this first discovery. Below, you can see the Double Edged Sword, by Celia Wilkinson3. When this picture doesn’t show a natural landscape, we can easily get the perspective of the scene, the fields, the trees, the light, even the temperature. The author reduced the scene to its concepts and the interpretation of them, transmitting a subjective point of view rather than an objective representation.

Let’s draw a simple schema to illustrate this change:
In classic art, human beings observe nature, process it, then produce a representation of nature. In abstract art, human beings observe their own productions (and their own thinking), process it, then produce abstract art, which can have an effect on other human beings without representing nature.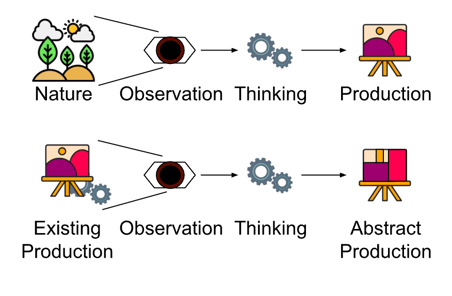
What about AI?
In the same way, AI models evolve in their own nature, which is human-produced data. They conceptualize this nature, then produce human-produced-like data.
There are two futures for AI. Either it will reach its limits and be stopped in all its glory, unable to learn more until humankind produces new learning data, leading to a sad I-do-what-humans-do-but-faster version of AI, or it will be able to consume its own production to create its own abstract art revolution. According to human history, such a future would lead to a rupture between AI production and the nature AI comes from, that is to say between AI productions and human productions. AI will produce new concepts, new ideas that we won’t be able to understand or even conceptualize. We’ll have to decide if we want to stop AI evolution or if we want to let AI models do what they do without being able to understand what they do, blindly trusting them to do the right thing.
So what now?
Will AI be reduced to being either a fast-but-late human ersatz or an uncontrollable genius?
Actually there is a big assumption that I didn’t really express: I wrote all this article considering AI models will only train on available public data. This is true, but not complete. As a company, you can totally decide to enrich your AI models with your own data, as long as you can guarantee that these AI models won’t be shared publicly. Therefore, there is still a field of data to train AI models: your own business activity. This data will never dry up, and it is the most reliable data for your own activity.
With a discovery tool, like Fast2 for instance, you can regularly scan your ECM and business environments to feed your AI models, and both ensure their constant improvement, and their relevance to your own business cases.
Sources
1 Stanford Institute for Human-Centered Artificial Intelligence (HAI), 2025 AI Index Report, accessed at https://hai.stanford.edu/ai-index/2025-ai-index-report
2 MBA Lyon (Museum of Fine Arts of Lyon), Violon – artwork record accessed at https://www.mba-lyon.fr/fr/fiche-oeuvre/violon
3 ScotlandArt Gallery, Celia Wilkinson – Double Edged Sword, artwork available at https://scotlandart.com/products/celia-wilkinson-double-edged-sword.